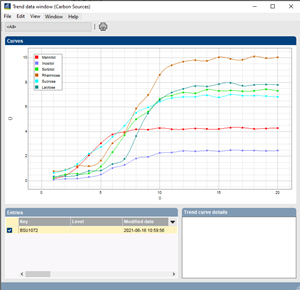
 Trend data includes all types of sequential readings that express an evolution of one parameter in function of another. Unlike character data, the measurements are not independent but together form a curve, through which a function can be fitted. The most prevalent trend data experiments are kinetic readings, i.e. the measurement of a parameter, for example a concentration of a product, in function of time. Examples are enzymatic activity measurements, real-time PCR, growth curves, etc. BIONUMERICS offers a large number of curve fit models, ranging from linear, logarithmic and Gaussian functions to more complex models such as logistic growth and Gompertz. In addition, a number of curve-derived parameters can be calculated to compare curve data in a sensible way. These parameters can be calculated dynamically as character values and used for clustering, identification and statistical data analysis.
Trend data includes all types of sequential readings that express an evolution of one parameter in function of another. Unlike character data, the measurements are not independent but together form a curve, through which a function can be fitted. The most prevalent trend data experiments are kinetic readings, i.e. the measurement of a parameter, for example a concentration of a product, in function of time. Examples are enzymatic activity measurements, real-time PCR, growth curves, etc. BIONUMERICS offers a large number of curve fit models, ranging from linear, logarithmic and Gaussian functions to more complex models such as logistic growth and Gompertz. In addition, a number of curve-derived parameters can be calculated to compare curve data in a sensible way. These parameters can be calculated dynamically as character values and used for clustering, identification and statistical data analysis.
Specifications
Analyze series of readings in function of a changing factor (time, temperature, etc.) that define a trend. Examples include bacterial growth curve data, kinetics of metabolic and enzymatic activity measurements, quantitative PCR (qPCR), or time-course experiments using microarrays.
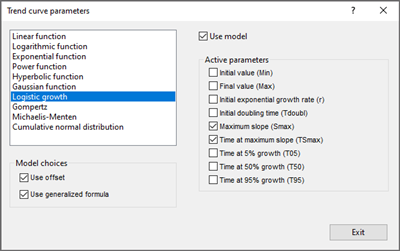
Curve fitting using any of twelve different models, including logistic growth, Gompertz, Gaussian, Hyperbolic, Power, Exponential, etc. with automatic parameter calculation, useful for analysis and comparison. The user can add custom parameters such as statistic parameters, slopes, and values at fixed X positions.
Comparison and clustering can be done on a selected parameter or a combination of multiple parameters. Comprehensive plotting tools with color and group indications.