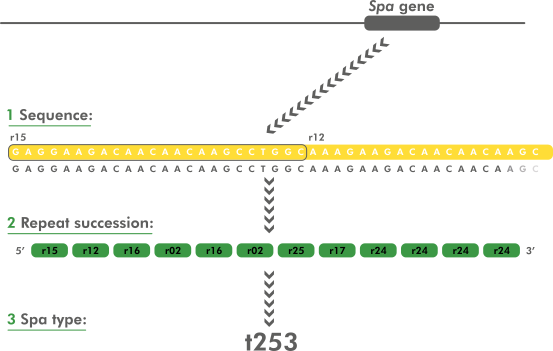
The spa typing technique uses the sequence of a polymorphic VNTR in the 3' coding region of the S. aureus-specific staphylococcal protein A (spa). Each new base composition of the polymorphic repeat found in a strain is assigned a unique repeat code. The repeat succession for a given strain determines its spa type. The individual repeat length for the spa VNTR is usually 24 bp, but exceptions of 21 to 30 exist. Although spa typing is a single-locus typing technique, it offers a subtyping resolution comparable to more expensive and/or laborious techniques such as MLST and PFGE. The technique is widely used for sub-typing of S. aureus in hospital and outbreak settings.
spa typing in BIONUMERICS
The BIONUMERICS software provides a fully automated workflow, from import of raw sequencer trace files to assignment of repeat codes and spa types. All problems or warnings during the workflow are reported and can be addressed with a single mouse click. BIONUMERICS automatically synchronizes repeat and spa type signatures with the SeqNet/Ridom Spa Server and instantly acquires new spa types from the Spa Server. In collaboration with SeqNet and Ridom GmbH, BIONUMERICS thereby uses the authentication and quality control protocols required by the server database.
Furthermore, BIONUMERICS offers a rich databasing and analysis platform, where spa typing data can be clustered and analyzed together with other subtyping data such as MLST, PFGE and any other phenotypic, genotypic, epidemiologic and geographic data.
Easy database setup
When you install the plugin, BIONUMERICS is configured automatically to contain the experiment types, database fields and settings for spa typing:
- Sequence and character experiments are created for the spa sequences and repeat successions, respectively.
- Start and stop trimming positions are stored in the spa assembly template but can be changed by the user whenever appropriate.
- Base calling quality control settings (PHRED based) are predefined according to the SeqNet criteria but can be changed by the user if no synchronization with SeqNet is required.
- Information fields are created for repeat successions, spa types, and optionally Kreiswirth notation and clonal complex information.
- Spa Server URLs for repeats and types are predefined but can be changed by the user if the server's URL changes.
- The software automatically downloads the repeat and type definitions at installation, and optionally, each time at database startup.
Full automatic processing workflow
- Automatic import and assembly of batches of sequencer trace files from various sources (AB, Beckman, Amersham, FASTA); file names are parsed into strain and gene information using a parsing definition.
- Consensus sequences are automatically trimmed using start and stop signatures and placed in the right direction.
- When the batch assembly is finished, an overview report is shown, listing status of each strain/gene combination.
- Double-click on a problem contig to display the detailed information window.
- Double-click on a particular problem to open the Assembler with the problem position selected.
- For each unknown or problem repeat, show nearest existing repeats and the differences in bases - easy verification with chromatograms.
- Repeat successions are instantly identified as spa types using the synchronized database, or can be uploaded to the Spa Server for identification.
- For new (non-existing) repeat successions, the Spa Server automatically generates a spa type and instantly returns the type assignment to BIONUMERICS.
- Calculate population modelling networks in the finest and most comprehensive cluster analysis application available today, using the DSI alignment model and Minimum Spanning Trees or phylogenetic clustering methods.
- Calculate and display partitioning for clonal complexes and use BIONUMERICS' rich set of statistics tools.